免费额度
看更新日志,可以发现更新很快,功能很强大。

通用的文字识别功能每天免费5万次,非常良心,除了特殊功能的场景,对于日常使用是肯定够了。

如何使用
官方也有一个快速教程
1. 成为开发者
三步完成账号的基本注册与认证:
- STEP1:点击百度AI开放平台导航右侧的控制台,选择需要使用的AI服务项。若为未登录状态,将跳转至登录界面,请您使用百度账号登录。如还未持有百度账户,可以点击此处注册百度账户。
- STEP2:首次使用,登录后将会进入开发者认证页面,请填写相关信息完成开发者认证。注:(如您之前已经是百度云用户或百度开发者中心用户,此步可略过。)
- STEP3:通过控制台左侧导航,选择产品服务-人工智能,进入具体AI服务项的控制面板(如文字识别、人脸识别)
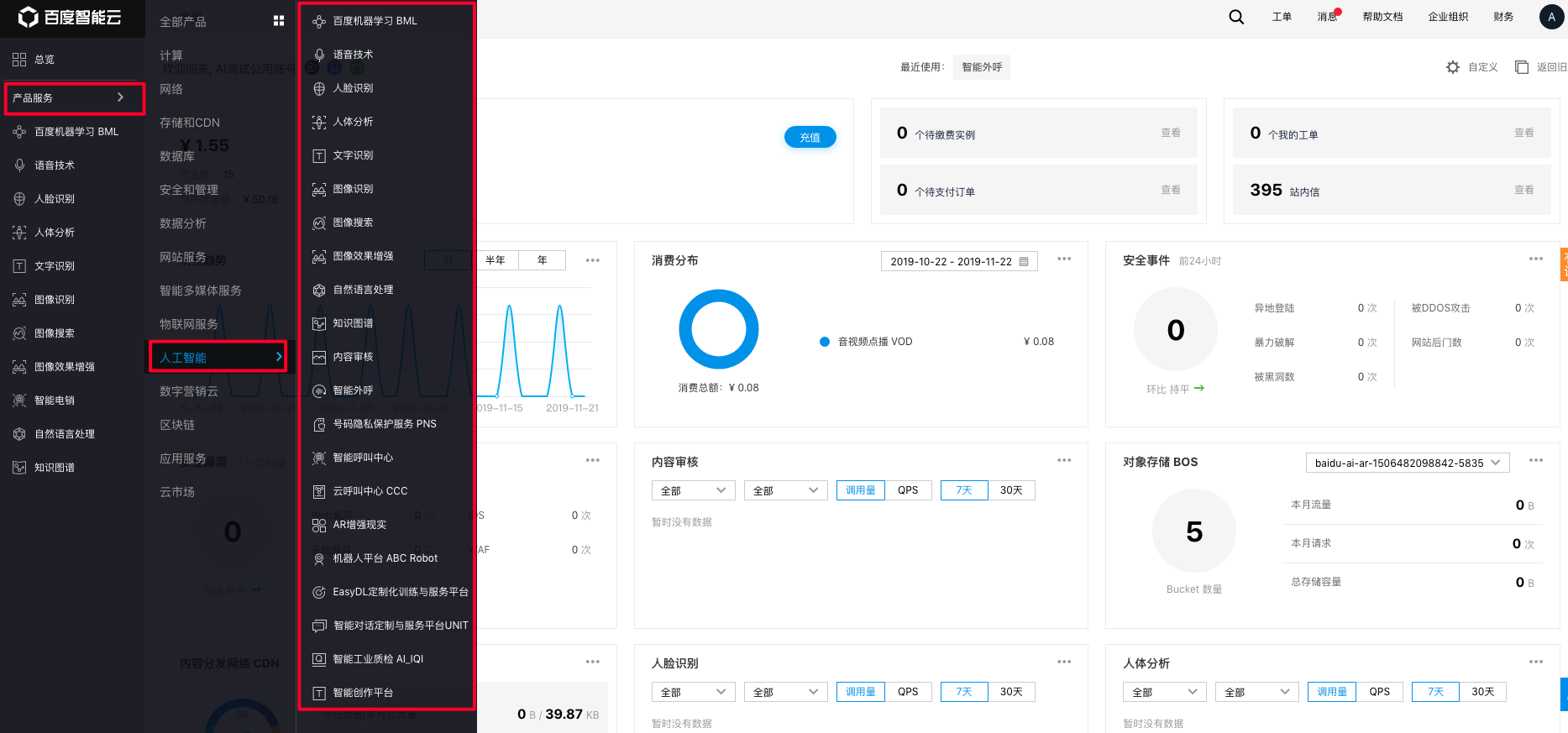
2. 创建应用
账号登录成功,您需要创建应用才可正式调用AI能力。应用是您调用API服务的基本操作单元,您可以基于应用创建成功后获取的API Key及Secret Key,进行接口调用操作,及相关配置。
您可按照下图所示的操作流程,完成创建操作。
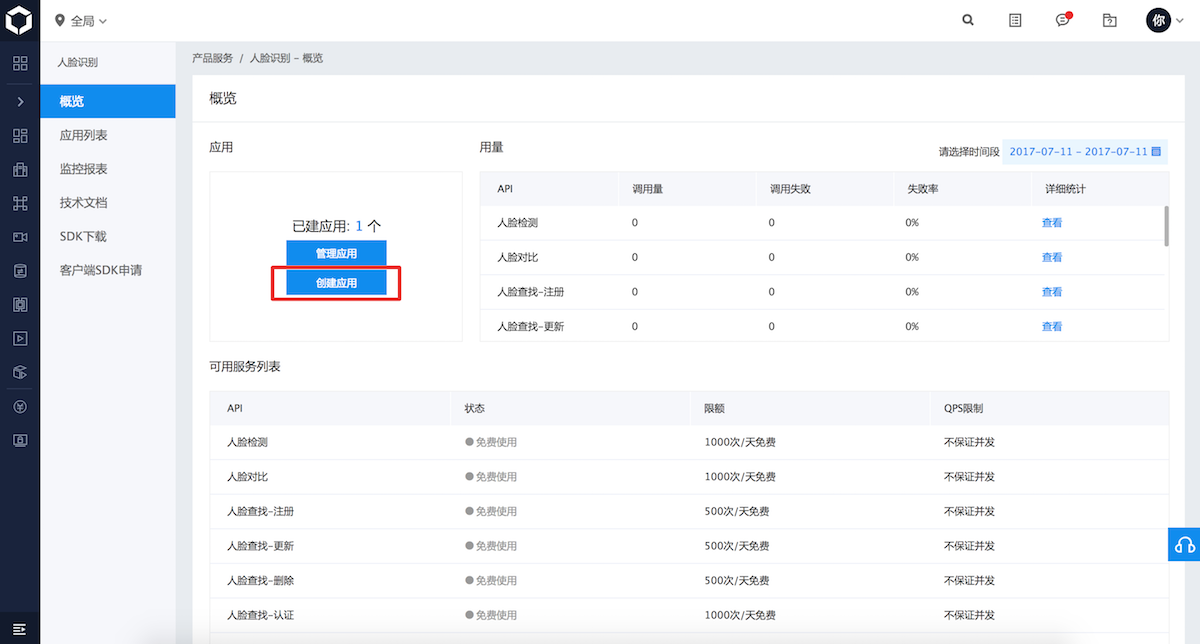 两种入口只是展现形式不同,相关AI服务模块内容完全一样 点击上图中的「创建应用」,即可进入应用创建界面,如下图所示:
两种入口只是展现形式不同,相关AI服务模块内容完全一样 点击上图中的「创建应用」,即可进入应用创建界面,如下图所示:
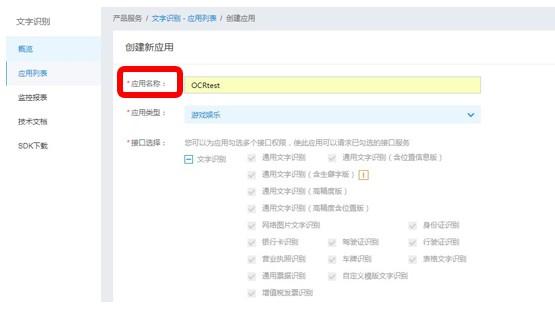
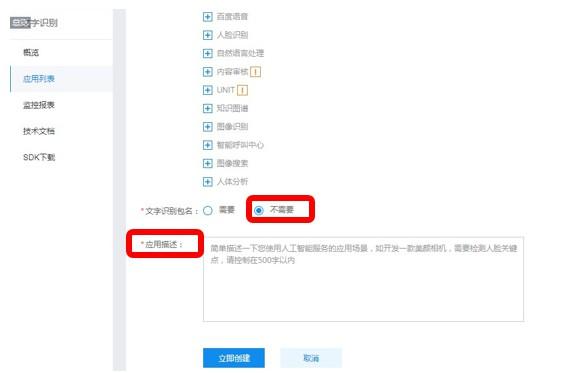
两种入口只是展现形式不同,相关AI服务模块内容完全一样 创建应用需填写的内容如下:
应用名称: 必填项,用于标识您所创建的应用的名称,支持中英文、数字、下划线及中横线,此名称一经创建完毕,不可修改;
应用类型: 必填项,根据您的应用的适用领域,在下拉列表中选取一个类型;
接口选择: 必填项,每个应用可以勾选业务所需的所有AI服务的接口权限(仅可勾选具备免费试用权限的接口能力),应用权限可跨服务勾选,创建应用完毕,此应用即具备了所勾选服务的调用权限;
填写完毕后,即可点击「立即创建」,完成应用的创建。应用创建完毕后,您可以点击左侧导航中的「应用列表」,进行应用查看,如下图红框部分所示:
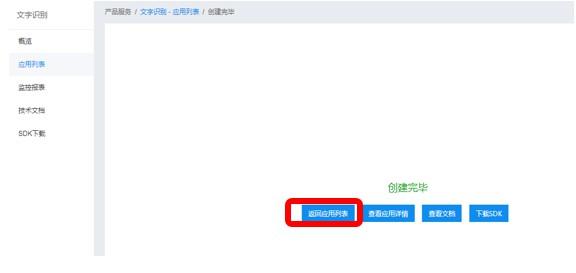
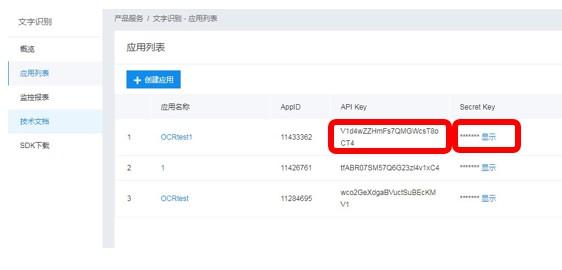
3. 获取密钥
在您创建完毕应用后,平台将会分配给您此应用的相关凭证,主要为AppID、API Key、Secret Key。示例:
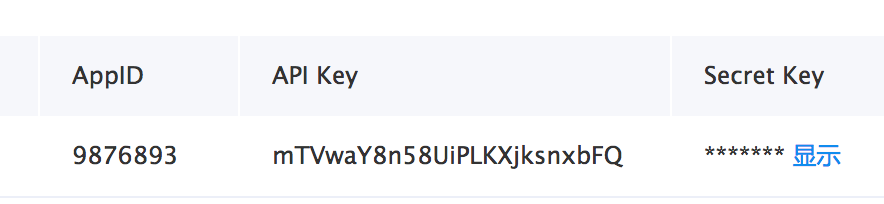 两种入口只是展现形式不同,相关AI服务模块内容完全一样
两种入口只是展现形式不同,相关AI服务模块内容完全一样
4. 生成签名
您需要使用创建应用所分配到的AppID、API Key及Secret Key,进行Access Token(用户身份验证和授权的凭证)的生成。
每种应用的生成方式略有不同,对于OCR,Token生成方式为:
# encoding:utf-8
import requests
# client_id 为官网获取的AK,
# client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
if response:
print(response.json())
5. 调用OCR接口
官方文档在通用文字识别(标准含位置版)给了示例, 其他版本方式也是一样的,只是请求的网址会有一点点不同
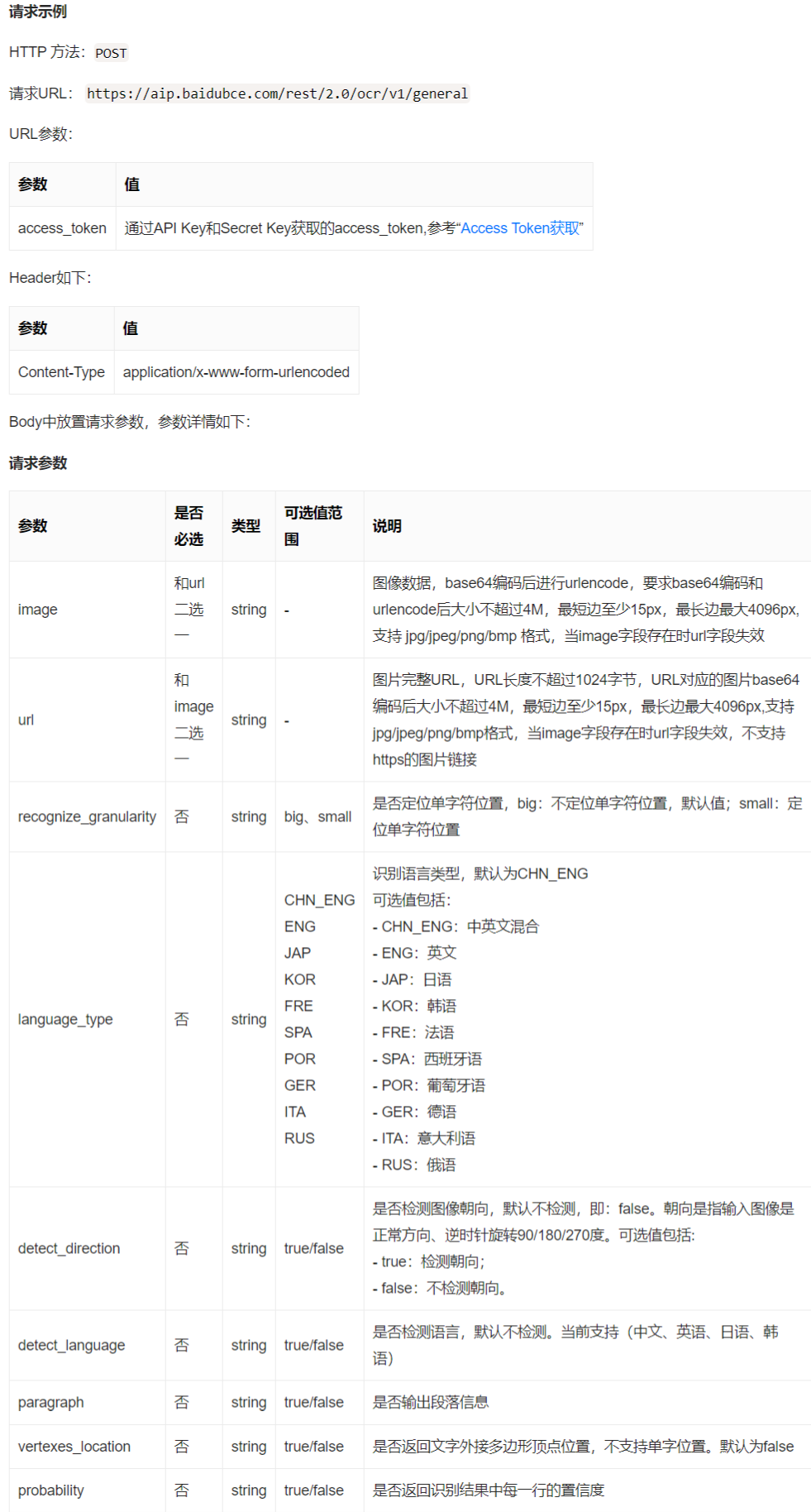
可以看到支持的语种也很多!
# encoding:utf-8
import requests
import base64
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general"
# 二进制方式打开图片文件
f = open('[本地文件]', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = '[调用鉴权接口获取的token]'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
这里仅需要更改access_token, 而他的获取方式要通过上一节的方式,而不是从百度AI开放平台复制的!
6.简单修改为更通用的函数
可以发现标准版与标准带位置版只在请求的URL处不一样,这样我们把这个位置作为参数传给函数,就可以切换接口了。
# -*- encoding: utf-8 -*-
import json
import requests
import base64
def get_words(fig_path, ocr_type="general"):
"""
:param fig_path:
:param ocr_type: general 标准含位置版 500次, general_basic 50000次
:return:
"""
request_url = f"https://aip.baidubce.com/rest/2.0/ocr/v1/{ocr_type}"
# 二进制方式打开图片文件
f = open(fig_path, 'rb')
img = base64.b64encode(f.read())
params = {"image": img}
# ! 改成你自己的AK和SK!!!
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=o5h0WAUse6ka5Y8xgV2WcGOA&client_secret=ScGdml5cwKwkaxK1KEDztY7plbFups18'
response = requests.get(host) # 获取access_token
if response:
res = response.json()
access_token = res["access_token"]
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
ocr_result = response.json()
print(json.dumps(ocr_result, indent=4, ensure_ascii=False))
words_result = "".join([words["words"] for words in ocr_result["words_result"]])
print(words_result)
return words_result
else:
return None
if __name__ == "__main__":
get_words(r"Snipaste_2020-09-28_15-54-01.png", 'general_basic')
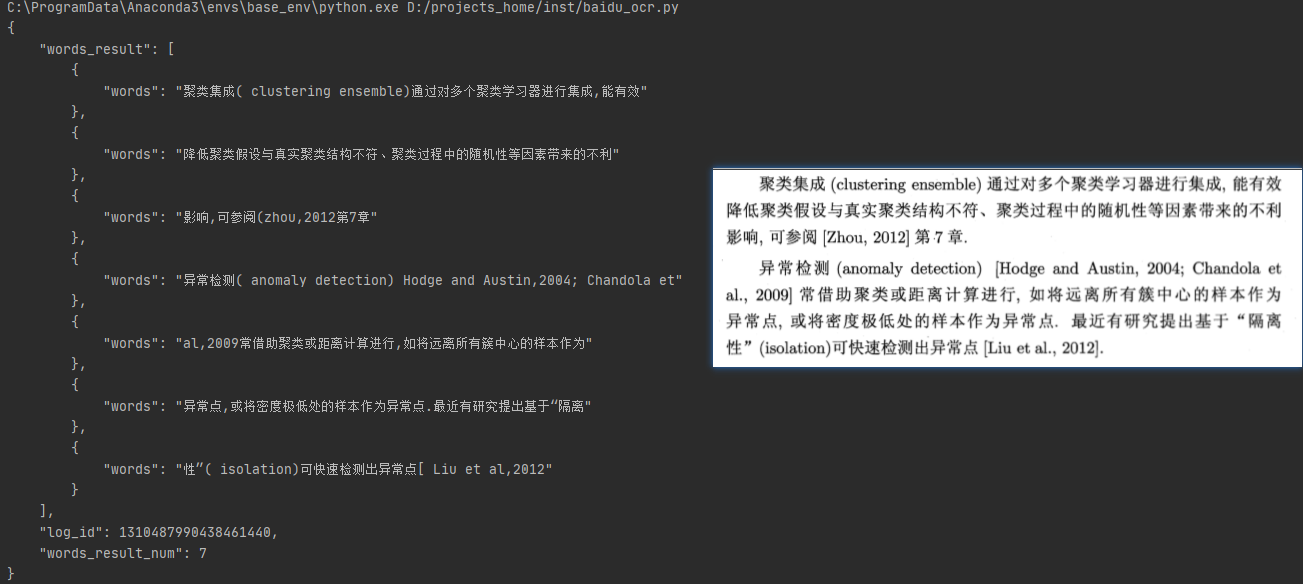
示例结果: